NonLinear Uncertainty Analysis - Monte Carlo
As we’ve seen, First-Order-Second-Moment (FOSM) is quick and insightful. But FOSM depends on an assumption that the relation between the model and the forecast uncertainty is linear. But many times the world is nonlinear. Short cuts like FOSM need assumptions, but we can free ourselves by taking the brute force approach. That is define the parameters that are important, provide the prior uncertainty, sample those parameters many times, run the model many times, and then summarize the results.
On a more practical standpoint, the underlying theory for FOSM and why it results in shortcomings can be hard to explain to stakeholders. Monte Carlo, however, is VERY straightforward, its computational brute force notwithstanding.
Here’s a flowchart from Anderson et al. (2015):
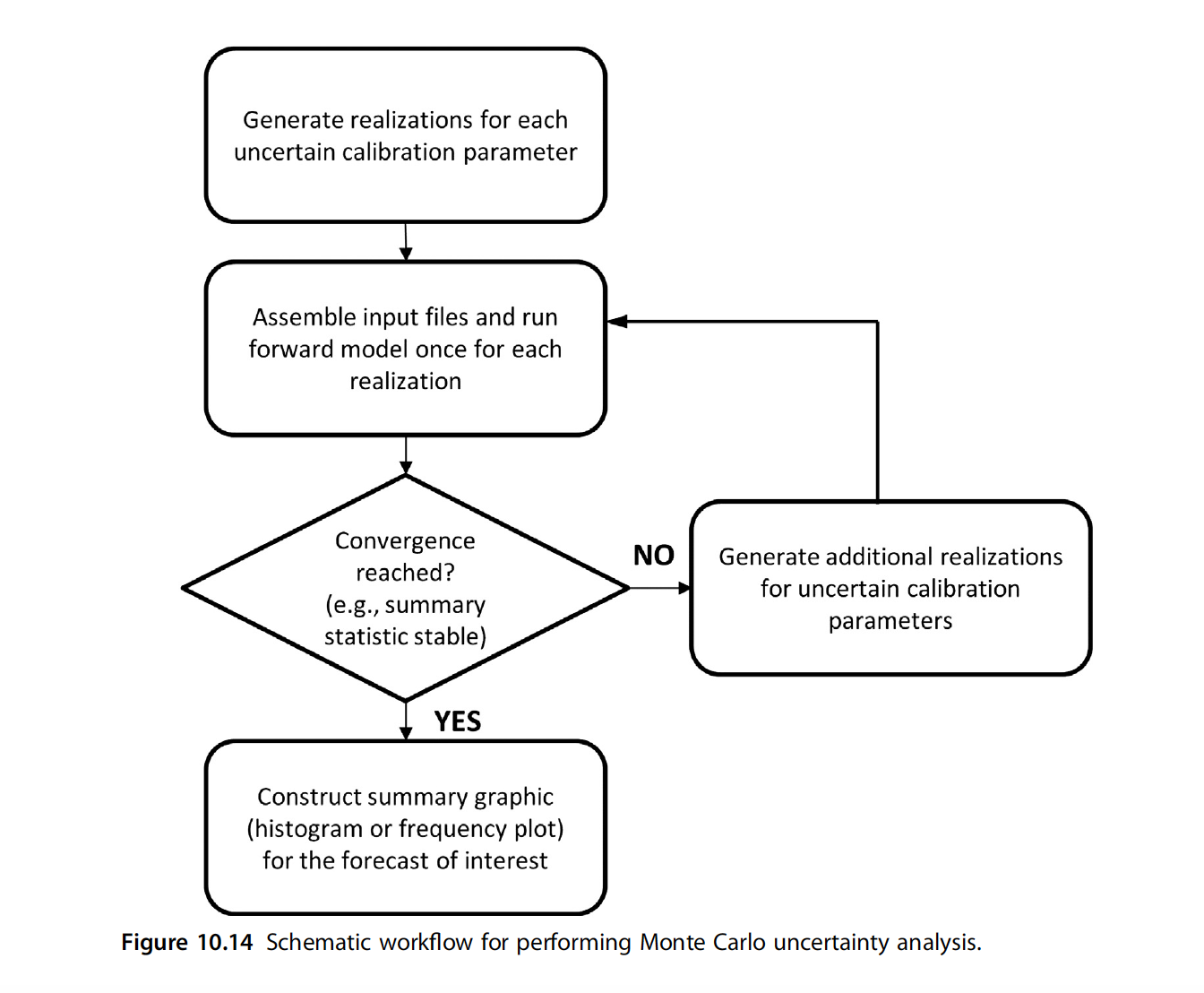
The Current Tutorial
In this notebook we will:
- Run Monte Carlo on the Freyberg model
- Look at parameter and forecast uncertainty
- Look at the effect of prior parameter uncertainty covariance
- Start thinking of the advantages and disadvantages of linear and nonlinear uncertainty methods
This notebook is going to be computationaly tough and may tax your computer. So buckle up.
Admin
First the usual admin of preparing folders and constructing the model and PEST datasets.
import sys
import os
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore", category=DeprecationWarning)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt;
import shutil
sys.path.insert(0,os.path.join("..", "..", "dependencies"))
import pyemu
import flopy
assert "dependencies" in flopy.__file__
assert "dependencies" in pyemu.__file__
sys.path.insert(0,"..")
import herebedragons as hbd
plt.rcParams['font.size'] = 10
pyemu.plot_utils.font =10
# folder containing original model files
org_d = os.path.join('..', '..', 'models', 'monthly_model_files_1lyr_newstress')
# a dir to hold a copy of the org model files
working_dir = os.path.join('freyberg_mf6')
if os.path.exists(working_dir):
shutil.rmtree(working_dir)
shutil.copytree(org_d,working_dir)
# get executables
hbd.prep_bins(working_dir)
# get dependency folders
hbd.prep_deps(working_dir)
# run our convenience functions to prepare the PEST and model folder
hbd.prep_pest(working_dir)
# convenience function that builds a new control file with pilot point parameters for hk
hbd.add_ppoints(working_dir)
ins file for heads.csv prepared.
ins file for sfr.csv prepared.
noptmax:0, npar_adj:1, nnz_obs:24
written pest control file: freyberg_mf6\freyberg.pst
could not remove start_datetime
1 pars added from template file .\freyberg6.sfr_perioddata_1.txt.tpl
6 pars added from template file .\freyberg6.wel_stress_period_data_10.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_11.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_12.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_2.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_3.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_4.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_5.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_6.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_7.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_8.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_9.txt.tpl
starting interp point loop for 800 points
took 2.029215 seconds
1 pars dropped from template file freyberg_mf6\freyberg6.npf_k_layer1.txt.tpl
29 pars added from template file .\hkpp.dat.tpl
starting interp point loop for 800 points
took 2.012059 seconds
29 pars added from template file .\rchpp.dat.tpl
noptmax:0, npar_adj:65, nnz_obs:37
new control file: 'freyberg_pp.pst'
Monte Carlo uses a lots and lots of forward runs so we don’t want to make the mistake of burning the silicon for a PEST control file that is not right. Here we make doubly sure that the control file has the recharge freed (not “fixed’ in the PEST control file).
Load the pst control file
Let’s double check what parameters we have in this version of the model using pyemu (you can just look in the PEST control file too.).
We have adjustable parameters that control SFR inflow rates, well pumping rates, hydraulic conductivity and recharge rates. Recall that by setting a parameter as “fixed” we are stating that we know it perfectly (should we though…?). Currently fixed parameters include porosity and future recharge.
For the sake of this tutorial, and as we did in the “sensitivity” tutorials, let’s set all the parameters free:
pst_name = "freyberg_pp.pst"
# load the pst
pst = pyemu.Pst(os.path.join(working_dir,pst_name))
#update parameter data
par = pst.parameter_data
#update paramter transform
par.loc[:, 'partrans'] = 'log'
# check if the model runs
pst.control_data.noptmax=0
# rewrite the control file
pst.write(os.path.join(working_dir,pst_name))
# run the model once
pyemu.os_utils.run('pestpp-glm freyberg_pp.pst', cwd=working_dir)
noptmax:0, npar_adj:68, nnz_obs:37
Reload the control file:
pst = pyemu.Pst(os.path.join(working_dir,'freyberg_pp.pst'))
pst.phi
131.79995788867873
Monte Carlo
In it’s simplest form, Monte Carlo boils down to: (1) “draw” many random samples of parameters from the prior probability distribution, (2) run the model, (3) look at the results.
So how do we “draw”, or sample, parameters? (Think “draw” as in “drawing a card from a deck”). We need to randomly sample parameter values from a range. This range is defined by the prior parameter probability distribution. As we did for FOSM, let’s assume that the bounds in the parameter data section define the range of a Gaussian (or normal) distribution, and that the intial values define the mean.
The Prior
We can use pyemu to sample parameter values from such a distribution. First, construct a covariance matrix from the parameter data in the pst control file:
prior_cov = pyemu.Cov.from_parameter_data(pst)
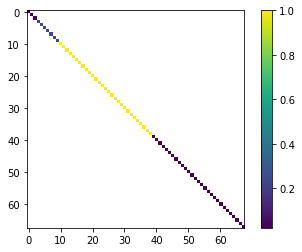
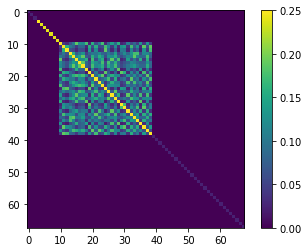
What did we do there? We generated a covariance matrix from the parameter bound values. The next cell displays an image of the matrix. As you can see, all off-diagonal values are zero. Therefore no parameter correaltion is accounted for.
This covariance matrix is the prior (before history matching) parameter covariance.
x = prior_cov.as_2d.copy()
x[x==0] = np.nan
plt.imshow(x)
plt.colorbar();
OK, let’s now sample 500 parameter sets from the probability distribution described by this covariance matrix and the mean values (e.g. the initial parameter values in the pst control file).
parensemble = pyemu.ParameterEnsemble.from_gaussian_draw(pst=pst,cov=prior_cov,num_reals=500,)
# ensure that the samples respect parameter bounds in the pst control file
parensemble.enforce()
Here’s an example of the first 5 parameter sets of our 500 created by our draw (“draw” here is like “drawing” a card
parensemble.head()
| ne1 | rch0 | rch1 | strinf | wel2 | wel1 | wel4 | wel5 | wel0 | wel3 | ... | rch_i:22_j:7_zone:1.0 | rch_i:37_j:17_zone:1.0 | rch_i:17_j:2_zone:1.0 | rch_i:12_j:12_zone:1.0 | rch_i:22_j:17_zone:1.0 | rch_i:2_j:17_zone:1.0 | rch_i:27_j:7_zone:1.0 | rch_i:32_j:12_zone:1.0 | rch_i:2_j:2_zone:1.0 | rch_i:12_j:2_zone:1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.008576 | 0.798390 | 1.097442 | 342.933067 | 900.000000 | 95.384015 | 673.122041 | 236.651598 | 93.555705 | 258.919768 | ... | 1.545899 | 0.967640 | 0.765540 | 0.879551 | 1.064152 | 1.094530 | 1.587063 | 1.764833 | 0.699708 | 0.969906 |
| 1 | 0.007612 | 1.908030 | 1.188849 | 594.907106 | 88.010442 | 118.664153 | 560.794560 | 900.000000 | 246.389133 | 660.090196 | ... | 1.470901 | 1.380243 | 1.047585 | 0.910253 | 0.688392 | 0.921585 | 0.984850 | 1.211731 | 0.994265 | 2.000000 |
| 2 | 0.009936 | 0.964648 | 0.670542 | 566.612120 | 95.205141 | 450.603288 | 468.262566 | 900.000000 | 121.221073 | 198.859473 | ... | 1.504745 | 1.025225 | 0.824225 | 1.357629 | 1.061188 | 0.805217 | 1.426085 | 1.235177 | 0.720202 | 0.742659 |
| 3 | 0.005000 | 0.862611 | 1.291555 | 1949.739433 | 134.206943 | 213.220396 | 900.000000 | 900.000000 | 65.534174 | 900.000000 | ... | 0.641770 | 1.531370 | 0.614023 | 1.068229 | 0.860114 | 0.942771 | 1.791559 | 1.428844 | 1.132330 | 0.736988 |
| 4 | 0.011502 | 1.170017 | 0.649204 | 582.673590 | 328.172742 | 56.132756 | 654.640273 | 263.797784 | 886.917946 | 301.128598 | ... | 1.157887 | 0.964998 | 0.950426 | 0.952610 | 1.437834 | 0.899621 | 1.234873 | 1.145106 | 0.844422 | 0.946133 |
5 rows × 68 columns
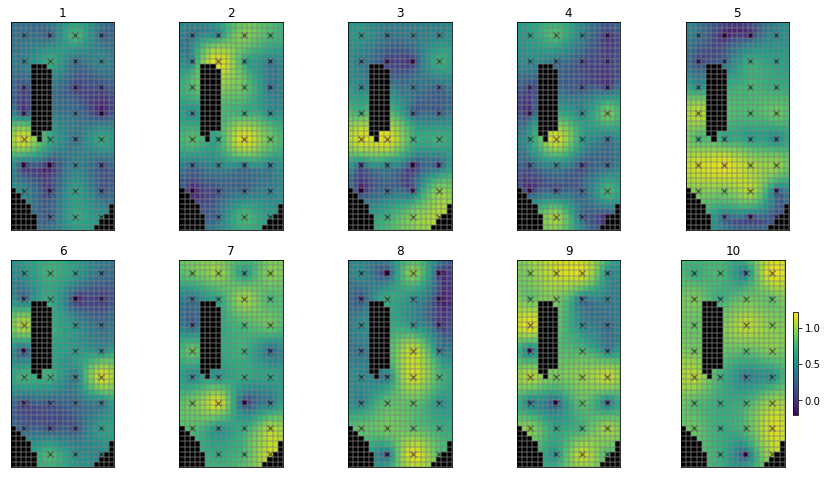
What does this look like in terms of spatially varying parameters? Let’s just plot the hydraulic conductivity from one of these samples. (Note the log-transformed values of K):
par = pst.parameter_data
parnmes = par.loc[par.pargp=='hk1'].parnme.values
pe_k = parensemble.loc[:,parnmes].copy()
# use the hbd convenienc function to plot several realisations
hbd.plot_ensemble_arr(pe_k, working_dir, 10)
could not remove start_datetime
return type uncaught, losing Ensemble type, returning DataFrame
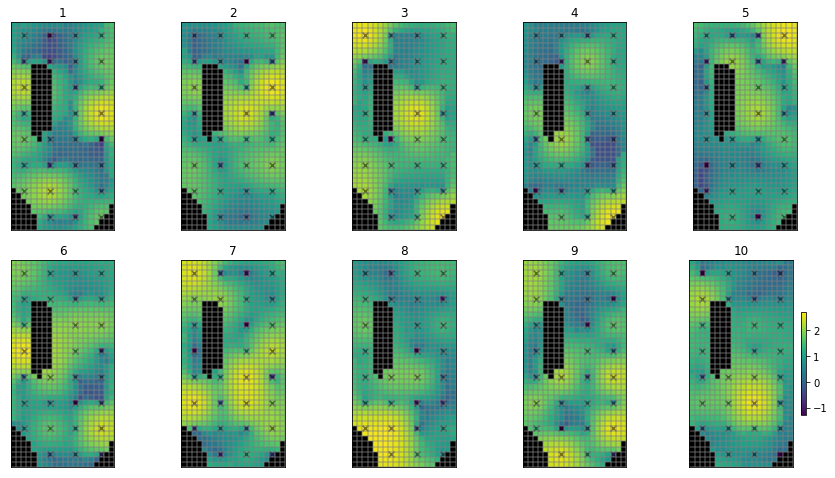
That does not look very realistic. Do these look “right” (from a geologic stand point)? Lots of “random” variation (pilot points spatially near each other can have very different values)…not much structure…why? Because we have not specified any parameter correlation. Each pilot point is statisticaly independent.
How do we express that in the prior? We need to express parameter spatial covariance with a geostatistical structure. Much the same as we did for regularization. Let’s build a covariance matrix for pilot point parameters.
You should be familiar with these by now:
v = pyemu.geostats.ExpVario(contribution=.25,a=3500,anisotropy=.8,bearing=1.0)
gs = pyemu.utils.geostats.GeoStruct(variograms=v)
# get the pilot point parameter info
df_pp = pyemu.pp_utils.pp_tpl_to_dataframe(os.path.join(working_dir,"hkpp.dat.tpl"))
df_pp.head()
| name | x | y | zone | parnme | |
|---|---|---|---|---|---|
| 0 | pp_0000 | 625.0 | 9375.0 | 1.0 | hk_i:2_j:2_zone:1.0 |
| 1 | pp_0001 | 1875.0 | 9375.0 | 1.0 | hk_i:2_j:7_zone:1.0 |
| 2 | pp_0002 | 3125.0 | 9375.0 | 1.0 | hk_i:2_j:12_zone:1.0 |
| 3 | pp_0003 | 4375.0 | 9375.0 | 1.0 | hk_i:2_j:17_zone:1.0 |
| 4 | pp_0004 | 625.0 | 8125.0 | 1.0 | hk_i:7_j:2_zone:1.0 |
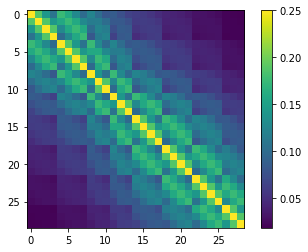
# construct the geostatistically informed covariance matrix for ppoint pars
cov = gs.covariance_matrix(df_pp.x,df_pp.y,df_pp.parnme)
# display
plt.imshow(cov.x,interpolation="nearest")
plt.colorbar()
cov.to_dataframe().head()
| hk_i:2_j:2_zone:1.0 | hk_i:2_j:7_zone:1.0 | hk_i:2_j:12_zone:1.0 | hk_i:2_j:17_zone:1.0 | hk_i:7_j:2_zone:1.0 | hk_i:7_j:7_zone:1.0 | hk_i:7_j:12_zone:1.0 | hk_i:7_j:17_zone:1.0 | hk_i:12_j:2_zone:1.0 | hk_i:12_j:12_zone:1.0 | ... | hk_i:27_j:7_zone:1.0 | hk_i:27_j:12_zone:1.0 | hk_i:27_j:17_zone:1.0 | hk_i:32_j:2_zone:1.0 | hk_i:32_j:7_zone:1.0 | hk_i:32_j:12_zone:1.0 | hk_i:32_j:17_zone:1.0 | hk_i:37_j:7_zone:1.0 | hk_i:37_j:12_zone:1.0 | hk_i:37_j:17_zone:1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| hk_i:2_j:2_zone:1.0 | 0.250000 | 0.187865 | 0.141173 | 0.106085 | 0.174922 | 0.158515 | 0.127735 | 0.099030 | 0.122390 | 0.100508 | ... | 0.041073 | 0.038509 | 0.034703 | 0.029333 | 0.028846 | 0.027335 | 0.025025 | 0.020238 | 0.019327 | 0.017905 |
| hk_i:2_j:7_zone:1.0 | 0.187865 | 0.250000 | 0.187865 | 0.141173 | 0.157961 | 0.174922 | 0.158515 | 0.127735 | 0.115596 | 0.116078 | ... | 0.041923 | 0.041073 | 0.038509 | 0.028718 | 0.029333 | 0.028846 | 0.027335 | 0.020524 | 0.020238 | 0.019327 |
| hk_i:2_j:12_zone:1.0 | 0.141173 | 0.187865 | 0.250000 | 0.187865 | 0.127129 | 0.157961 | 0.174922 | 0.158515 | 0.099806 | 0.122390 | ... | 0.040891 | 0.041923 | 0.041073 | 0.027099 | 0.028718 | 0.029333 | 0.028846 | 0.020148 | 0.020524 | 0.020238 |
| hk_i:2_j:17_zone:1.0 | 0.106085 | 0.141173 | 0.187865 | 0.250000 | 0.098518 | 0.127129 | 0.157961 | 0.174922 | 0.081563 | 0.115596 | ... | 0.038182 | 0.040891 | 0.041923 | 0.024714 | 0.027099 | 0.028718 | 0.029333 | 0.019158 | 0.020148 | 0.020524 |
| hk_i:7_j:2_zone:1.0 | 0.174922 | 0.157961 | 0.127129 | 0.098518 | 0.250000 | 0.187865 | 0.141173 | 0.106085 | 0.174922 | 0.127735 | ... | 0.058374 | 0.053897 | 0.047526 | 0.041923 | 0.041073 | 0.038509 | 0.034703 | 0.028846 | 0.027335 | 0.025025 |
5 rows × 29 columns
cov_df = cov.to_dataframe()
prior_cov = prior_cov.to_dataframe()
#update values for hk ppoint parameters
prior_cov.loc[cov_df.index.values, cov_df.columns] = cov_df.values
# make Cov object again
prior_cov = pyemu.Cov.from_dataframe(prior_cov)
# display
plt.imshow(prior_cov.x,interpolation="nearest")
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x1df6486b250>
Now re-sample using the geostatisticaly informed prior:
parensemble = pyemu.ParameterEnsemble.from_gaussian_draw(pst=pst, cov=prior_cov, num_reals=500,)
# ensure that the samples respect parameter bounds in the pst control file
parensemble.enforce()
drawing from group hk1
drawing from group porosity
drawing from group rch0
drawing from group rch1
drawing from group rchpp
drawing from group strinf
drawing from group wel
Here’s an example of the first 5 parameter sets of our 500 created by our draw (“draw” here is like “drawing” a card
parensemble.head()
| ne1 | rch0 | rch1 | strinf | wel2 | wel1 | wel4 | wel5 | wel0 | wel3 | ... | rch_i:22_j:7_zone:1.0 | rch_i:37_j:17_zone:1.0 | rch_i:17_j:2_zone:1.0 | rch_i:12_j:12_zone:1.0 | rch_i:22_j:17_zone:1.0 | rch_i:2_j:17_zone:1.0 | rch_i:27_j:7_zone:1.0 | rch_i:32_j:12_zone:1.0 | rch_i:2_j:2_zone:1.0 | rch_i:12_j:2_zone:1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.009583 | 0.636000 | 1.208663 | 296.866418 | 109.590198 | 143.473132 | 900.000000 | 347.261007 | 148.383135 | 90.848116 | ... | 1.596587 | 0.958090 | 0.721037 | 1.729436 | 1.744553 | 0.719409 | 1.243979 | 1.195635 | 0.681879 | 1.176365 |
| 1 | 0.012451 | 2.000000 | 1.358884 | 401.349422 | 164.705488 | 900.000000 | 386.662038 | 76.166170 | 900.000000 | 69.328231 | ... | 0.603213 | 0.772045 | 1.321382 | 0.859291 | 0.828841 | 1.282602 | 1.006906 | 0.851859 | 0.889863 | 0.998289 |
| 2 | 0.009922 | 1.966333 | 1.142492 | 245.576160 | 421.100437 | 110.117281 | 145.506390 | 201.207688 | 510.979844 | 900.000000 | ... | 0.883169 | 1.202958 | 0.728151 | 0.934369 | 1.187185 | 1.646549 | 1.849163 | 1.266836 | 0.941629 | 0.909086 |
| 3 | 0.007218 | 0.588905 | 0.567419 | 626.098148 | 71.219612 | 900.000000 | 355.428866 | 227.579461 | 156.658614 | 207.097135 | ... | 0.938810 | 1.209241 | 1.895610 | 1.089464 | 0.638541 | 1.510416 | 1.009344 | 0.525180 | 1.542154 | 0.908281 |
| 4 | 0.008293 | 0.922642 | 1.029767 | 476.002182 | 44.652183 | 795.533096 | 21.292506 | 900.000000 | 544.941314 | 826.396753 | ... | 0.832306 | 1.097875 | 0.942772 | 0.916822 | 0.875572 | 0.894957 | 0.539972 | 0.687725 | 0.753373 | 0.994329 |
5 rows × 68 columns
Now when we plot the spatialy distributed parameters (hk1), it still doesn’t look very “natural”, but at least we can see some structure and points which are near to each other are more ikely to be similar:
pe_k = parensemble.loc[:,parnmes].copy()
# use the hbd convenienc function to plot several realisations
hbd.plot_ensemble_arr(pe_k, working_dir, 10)
could not remove start_datetime
return type uncaught, losing Ensemble type, returning DataFrame
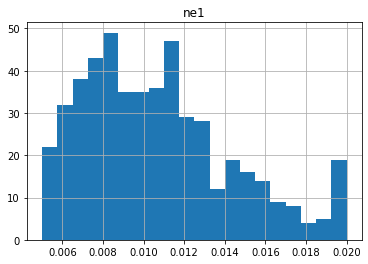
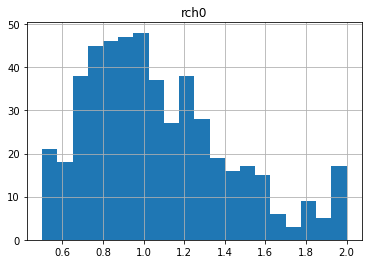
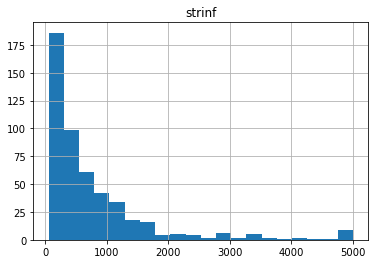
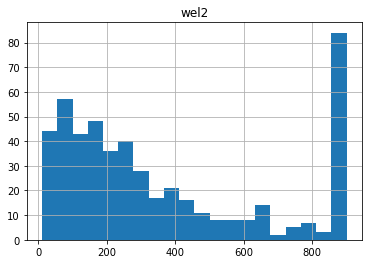
Let’s look at some of the distributions. Note that distributions are log-normal, because parameters in the pst are log-transformed:
for pname in pst.par_names[:5]:
ax = parensemble.loc[:,pname].hist(bins=20)
print(parensemble.loc[:,pname].min(),parensemble.loc[:,pname].max(),parensemble.loc[:,pname].mean())
ax.set_title(pname)
plt.show()
0.005 0.02 0.01067691804894108
0.5 2.0 1.0730318679538804
0.5 2.0 1.0685975451074596
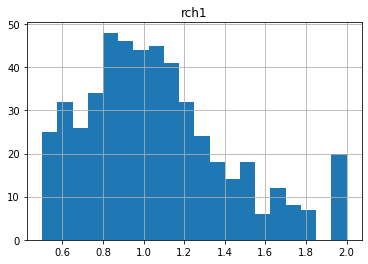
50.0 5000.0 773.0894942537367
11.121848658985792 900.0 364.8164629415672
Notice anything funny? Compare these distributions to the uper/lower bounds in the pst.parameter_data. There seem to be many parameters “bunched up” at the bounds. This is due to the gaussian distribution being truncated at the parameter bounds.
pst.parameter_data.head()
| parnme | partrans | parchglim | parval1 | parlbnd | parubnd | pargp | scale | offset | dercom | extra | i | j | zone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| parnme | ||||||||||||||
| ne1 | ne1 | log | factor | 0.01 | 0.005 | 0.02 | porosity | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| rch0 | rch0 | log | factor | 1.00 | 0.500 | 2.00 | rch0 | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| rch1 | rch1 | log | factor | 1.00 | 0.500 | 2.00 | rch1 | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| strinf | strinf | log | factor | 500.00 | 50.000 | 5000.00 | strinf | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| wel2 | wel2 | log | factor | 300.00 | 10.000 | 900.00 | wel | -1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
Run Monte Carlo
So we now have 500 different random samples of parameters. Let’s run them! This is going to take some time, so let’s do it in parallel using PEST++SWP.
First write the ensemble to an external CSV file:
parensemble.to_csv(os.path.join(working_dir,"sweep_in.csv"))
As usual, make sure to specify the number of agents to use. This value must be assigned according to the capacity of youmachine:
num_workers = 10
# the master directory
m_d='master_mc'
Run the next cell to call PEST++SWP. It’ll take a while.
pyemu.os_utils.start_workers(working_dir, # the folder which contains the "template" PEST dataset
'pestpp-swp', #the PEST software version we want to run
pst_name, # the control file to use with PEST
num_workers=num_workers, #how many agents to deploy
worker_root='.', #where to deploy the agent directories; relative to where python is running
master_dir=m_d, #the manager directory
)
Alright - let’s see some MC results. For these runs, what was the Phi?
df_out = pd.read_csv(os.path.join(m_d,"sweep_out.csv"),index_col=0)
df_out.iloc[:,:] = df_out.iloc[:,:].astype(float)
df_out = df_out.loc[df_out.failed_flag==0,:] #drop any failed runs
df_out = df_out.loc[~df_out.le(-2.e10).any(axis=1)] #drop extreme values
df_out.columns = [c.lower() for c in df_out.columns]
df_out.head()
| input_run_id | failed_flag | phi | meas_phi | regul_phi | gage-1 | headwater | particle | tailwater | trgw-0-13-10 | ... | trgw-0-9-1:4108.5 | trgw-0-9-1:4138.5 | trgw-0-9-1:4169.5 | trgw-0-9-1:4199.5 | trgw-0-9-1:4230.5 | trgw-0-9-1:4261.5 | trgw-0-9-1:4291.5 | trgw-0-9-1:4322.5 | trgw-0-9-1:4352.5 | trgw-0-9-1:4383.5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| run_id | |||||||||||||||||||||
| 0 | 0.0 | 0.0 | 619.576222 | 619.576222 | 0.0 | 474.232111 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 37.466570 | 37.750637 | 37.973004 | 38.068521 | 38.020843 | 37.846665 | 37.605281 | 37.350871 | 37.168975 | 37.156842 |
| 1 | 1.0 | 0.0 | 4634.898463 | 4634.898463 | 0.0 | 2769.610344 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 41.156702 | 41.485288 | 42.029705 | 42.690176 | 41.812960 | 41.470349 | 41.086245 | 40.710035 | 40.432904 | 40.352933 |
| 2 | 2.0 | 0.0 | 2765.490874 | 2765.490874 | 0.0 | 2446.710514 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 37.892667 | 37.974050 | 38.000180 | 37.922830 | 37.719802 | 37.417057 | 37.076874 | 36.744300 | 36.503167 | 36.435266 |
| 3 | 3.0 | 0.0 | 989.876635 | 989.876635 | 0.0 | 793.829044 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 36.248752 | 36.296259 | 36.317630 | 36.286879 | 36.190321 | 36.037679 | 35.858439 | 35.673592 | 35.527561 | 35.462595 |
| 4 | 4.0 | 0.0 | 795.308698 | 795.308698 | 0.0 | 609.907811 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 52.069763 | 54.383517 | 53.807098 | 50.581377 | 46.030802 | 42.632138 | 41.985583 | 41.952356 | 41.962384 | 42.729573 |
5 rows × 423 columns
Wow, some are pretty large. What was Phi with the initial parameter values??
pst.phi
131.79995788867873
Let’s plot Phi for all 500 runs:
df_out.meas_phi.hist(bins=100);
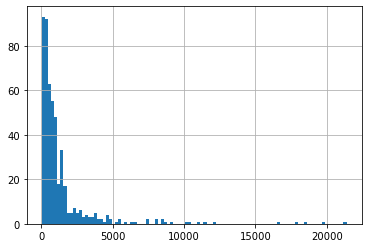
Wow, some of those models are really REALLY bad fits to the observations. So, when we only use our prior knowledge to sample the parameters we get a bunch of models with unacceptably Phi, and we can consider them not reasonable. Therefore, we should NOT include them in our uncertainty analysis.
Conditioning (a.k.a GLUE)
IMPORTANT: this is super important - in this next block we are “conditioning” our Monte Carlo run by removing the bad runs based on a Phi cutoff. So here is where we choose which realizations we consider good enough with respect to fitting the observation data.
Those realizations with a phi bigger than our cutoff are out, no matter how close to the cutoff; those that are within the cutoff are all considered equally good regardless of how close to the cutoff they reside.
We started out with a Phi of:
pst.phi
131.79995788867873
Let’s say any Phi below 2x pst.phi is aceptable (which is pretty poor by the way…):
acceptable_phi = pst.phi * 2
good_enough = df_out.loc[df_out.phi<acceptable_phi].index.values
print("number of good enough realisations:", good_enough.shape[0])
number of good enough realisations: 90
These are the run number of the 500 that met this cutoff. Sheesh - that’s very few!
Here is a major problem with “rejection sampling” in high dimensions: you have to run the model many many many many many times to find even a few realizations that fit the data acceptably well.
With all these parameters, there are so many possible combinations, that very few realizations fit the data very well…we will address this problem later, so for now, let bump our “good enough” threshold to some realizations to plot.
Let’s plot just these “good” ones:
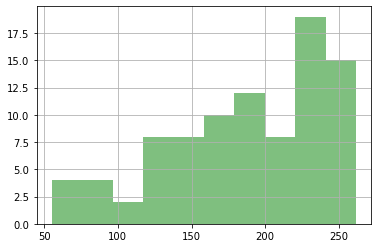
#ax = df_out.phi.hist(alpha=0.5)
df_out.loc[good_enough,"phi"].hist(color="g",alpha=0.5)
plt.show()
Now the payoff - using our good runs, let’s make some probablistic plots! Here’s our parameters
Gray blocks the full the range of the realizations. These are within our bounds of reasonable given what we knew when we started, so those grey boxes represent our prior
The blue boxes show the runs that met our criteria, so that distribution represents our posterior
for parnme in pst.par_names[:5]:
ax = plt.subplot(111)
parensemble.loc[:,parnme].hist(bins=10,alpha=0.5,color="0.5",ax=ax,)
parensemble.loc[good_enough,parnme].hist(bins=10,alpha=0.5,color="b",ax=ax,)
ax.set_title(parnme)
plt.ylabel('count')
plt.tight_layout()
plt.show()
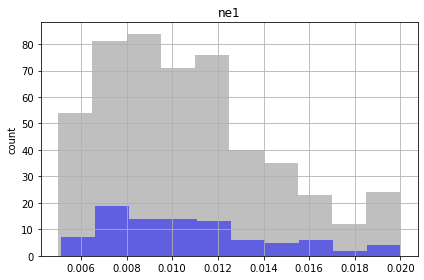
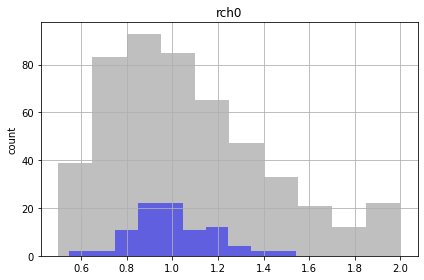
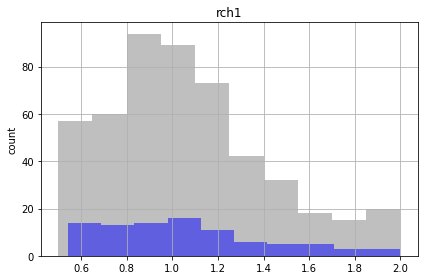
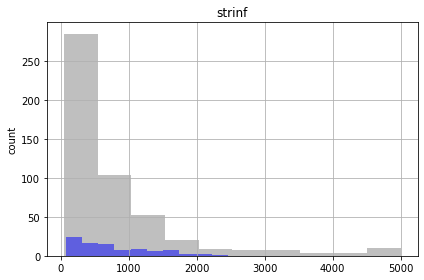
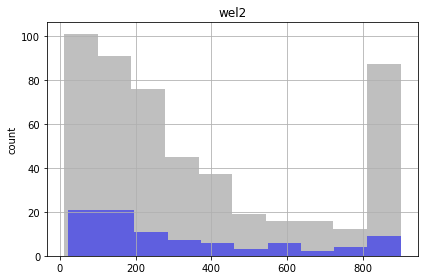
Similar to the FOSM results, the future recharge (rch1) and porosity (ne1) are not influenced by calibration. The conditioned parameter values should cover the same range as unconditioned values.
Let’s look at the forecasts
In the plots below, prior forecast distributions are shaded grey, posteriors are graded blue and the “true” value is shown as dashed black line.
for forecast in pst.forecast_names:
ax = plt.subplot(111)
df_out.loc[:,forecast].hist(bins=10,alpha=0.5,color="0.5",ax=ax)
df_out.loc[good_enough,forecast].hist(bins=10,alpha=0.5,color="b",ax=ax)
v = pst.observation_data.loc[forecast,"obsval"]
ylim = ax.get_ylim()
ax.plot([v,v],ylim,"k--",lw=2.0)
ax.set_ylabel('count')
ax.set_title(forecast)
plt.tight_layout()
plt.show()
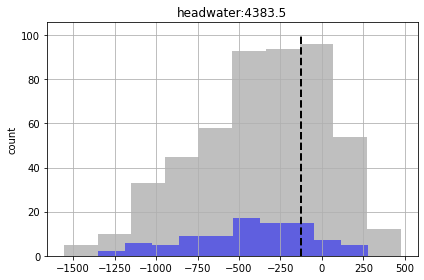
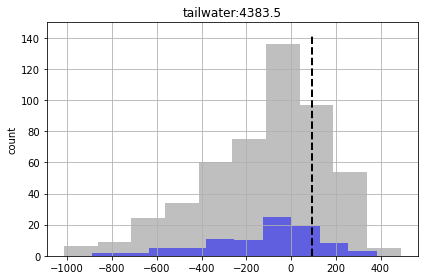
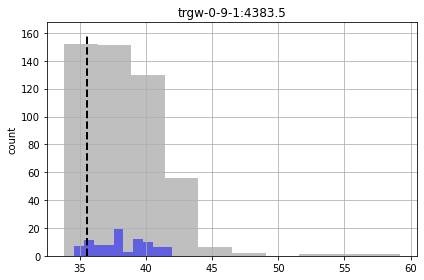
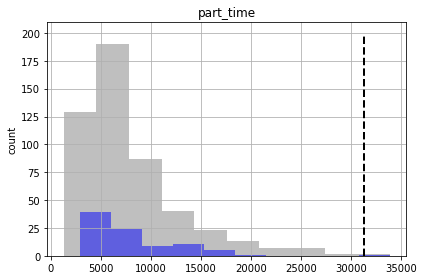
We see for some of the foreacsts that the prior and posterior are similar - indicating that “calibration” hasn’t helped reduce forecast uncertainty. That being said, given the issues noted above for high-dimensional conditioned-MC, the very very few realisations we are using here to assess the posterior make it a bit dubious.
And, as you can see, some of the true forecast values are not being covered by the posterior. So - failing.
Its hard to say how the posterior compares to the prior with so few “good enough” realizations. To fix this problem, we have two choices:
- run the model more times for Monte Carlo (!)
- generate realizations that fix the data better before hand
Advanced Monte Carlo - sampling from the linearized posterior
In the previous section, we saw that none of the realizations fit the observations anywhere close to phimlim because of the dimensionality of the pilot point problem.
Here, we will use so linear algebra trickeration to “pre-condition” the realizations so that they have a better chance of fitting the observations. As we all know now, “linear algebra” = Jacobian!
First we need to run the calibration process to get the calibrated parameters and last Jacobian. Let’s do that quick-sticks now. The next cell repeats what we did during the “freyberg regularization” tutorial. It can take a while.
hbd.prep_mc(working_dir)
getting CC matrix
processing
noptmax:20, npar_adj:68, nnz_obs:37
%load_ext autoreload
%autoreload 2
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
#new name
pst_name = "freyberg_reg.pst"
m_d = 'master_amc'
pyemu.os_utils.start_workers(working_dir, # the folder which contains the "template" PEST dataset
'pestpp-glm', #the PEST software version we want to run
pst_name, # the control file to use with PEST
num_workers=num_workers, #how many agents to deploy
worker_root='.', #where to deploy the agent directories; relative to where python is running
master_dir=m_d, #the manager directory
)
pst = pyemu.Pst(os.path.join(m_d, pst_name))
schur bayesian monte carlo
Here, we will swap out the prior parameter covariance matrix ($\boldsymbol{\Sigma}{\theta}$) for the FOSM-based posterior parameter covariance matrix ($\overline{\boldsymbol{\Sigma}}{\theta}$). Everything else is exactly the same (sounds like a NIN song).
First instantiate a the pyemu.Schur object:
sc = pyemu.Schur(jco=os.path.join(m_d,pst_name.replace(".pst",".jcb")),
pst=pst,
parcov=prior_cov) # geostatistically informed prior covariance matrix we built earlier
Update the control file with the “best fit” parameters (e.g. the calibrated parameters). These values are the mean ofthe posterior parameter probability distribution.
sc.pst.parrep(os.path.join(m_d,pst_name.replace(".pst",".parb")))
parrep: updating noptmax to 0
Now we sample parameters from the linearized (because it is based on the linear analysis/FOSM derived posterior) posterior probability dristribution. We obtain the mean of the distribution from the calibrated parameters (the parameter values of minimum error variance). We obtain the variance from the posterior parameter covariance matrix ($X^{t}QX$).
sc.pst.parameter_data
| parnme | partrans | parchglim | parval1 | parlbnd | parubnd | pargp | scale | offset | dercom | extra | i | j | zone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| parnme | ||||||||||||||
| ne1 | ne1 | log | factor | 0.01 | 0.005 | 0.02 | porosity | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| rch0 | rch0 | log | factor | 1.00 | 0.500 | 2.00 | rch0 | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| rch1 | rch1 | log | factor | 1.00 | 0.500 | 2.00 | rch1 | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| strinf | strinf | log | factor | 500.00 | 50.000 | 5000.00 | strinf | 1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| wel2 | wel2 | log | factor | 300.00 | 10.000 | 900.00 | wel | -1.0 | 0.0 | 1 | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| rch_i:2_j:17_zone:1.0 | rch_i:2_j:17_zone:1.0 | log | factor | 1.00 | 0.500 | 2.00 | rchpp | 1.0 | 0.0 | 1 | NaN | 2 | 17 | 1.0 |
| rch_i:27_j:7_zone:1.0 | rch_i:27_j:7_zone:1.0 | log | factor | 1.00 | 0.500 | 2.00 | rchpp | 1.0 | 0.0 | 1 | NaN | 27 | 7 | 1.0 |
| rch_i:32_j:12_zone:1.0 | rch_i:32_j:12_zone:1.0 | log | factor | 1.00 | 0.500 | 2.00 | rchpp | 1.0 | 0.0 | 1 | NaN | 32 | 12 | 1.0 |
| rch_i:2_j:2_zone:1.0 | rch_i:2_j:2_zone:1.0 | log | factor | 1.00 | 0.500 | 2.00 | rchpp | 1.0 | 0.0 | 1 | NaN | 2 | 2 | 1.0 |
| rch_i:12_j:2_zone:1.0 | rch_i:12_j:2_zone:1.0 | log | factor | 1.00 | 0.500 | 2.00 | rchpp | 1.0 | 0.0 | 1 | NaN | 12 | 2 | 1.0 |
68 rows × 14 columns
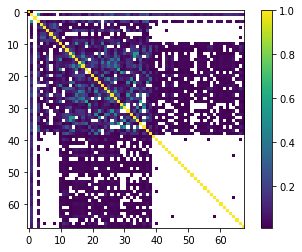
x = abs(sc.posterior_parameter.to_pearson().x)
x[x<0.01]=np.nan
plt.imshow(x)
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x1df6a386b50>
parensemble = pyemu.ParameterEnsemble.from_gaussian_draw(pst=sc.pst,
cov=sc.posterior_parameter, # posterior parameter covariance
num_reals=500,)
drawing from group hk1
drawing from group porosity
drawing from group rch0
drawing from group rch1
drawing from group rchpp
drawing from group strinf
drawing from group wel
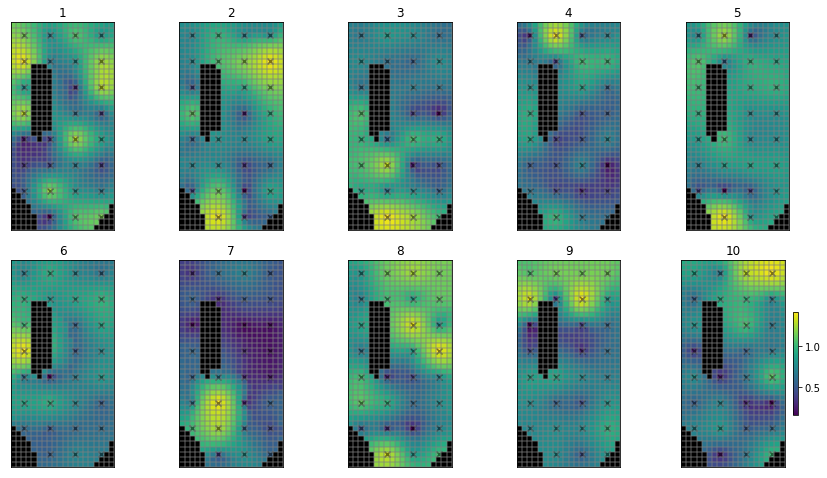
What do these look like?
pe_k = parensemble.loc[:,parnmes].copy()
# use the hbd convenienc function to plot several realisations
hbd.plot_ensemble_arr(pe_k, working_dir, 10)
could not remove start_datetime
return type uncaught, losing Ensemble type, returning DataFrame
As before, write the file for PEST++SWP:
parensemble.to_csv(os.path.join(working_dir,"sweep_in.csv"))
And run again:
pyemu.os_utils.start_workers(working_dir, # the folder which contains the "template" PEST dataset
'pestpp-swp', #the PEST software version we want to run
pst_name, # the control file to use with PEST
num_workers=num_workers, #how many agents to deploy
worker_root='.', #where to deploy the agent directories; relative to where python is running
master_dir=m_d, #the manager directory
)
And pull in the results, just as before:
df_out = pd.read_csv(os.path.join(m_d,"sweep_out.csv"),index_col=0,)
df_out.iloc[:,:] = df_out.iloc[:,:].astype(float)
df_out = df_out.loc[df_out.failed_flag==0,:] #drop any failed runs
df_out = df_out.loc[~df_out.le(-2.e10).any(axis=1)] #drop extreme values
df_out = df_out.loc[df_out.meas_phi<1e10] #drop extreme values
df_out.columns = [c.lower() for c in df_out.columns]
df_out.head()
| input_run_id | failed_flag | phi | meas_phi | regul_phi | gage-1 | headwater | particle | tailwater | trgw-0-13-10 | ... | trgw-0-9-1:4108.5 | trgw-0-9-1:4138.5 | trgw-0-9-1:4169.5 | trgw-0-9-1:4199.5 | trgw-0-9-1:4230.5 | trgw-0-9-1:4261.5 | trgw-0-9-1:4291.5 | trgw-0-9-1:4322.5 | trgw-0-9-1:4352.5 | trgw-0-9-1:4383.5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| run_id | |||||||||||||||||||||
| 0 | 0.0 | 0.0 | NaN | 1322.291485 | NaN | 1222.341259 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 36.740411 | 36.787046 | 36.803979 | 36.761189 | 36.642000 | 36.458180 | 36.244836 | 36.026991 | 35.857205 | 35.785682 |
| 1 | 1.0 | 0.0 | NaN | 191.203343 | NaN | 178.238114 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 40.474222 | 40.373511 | 40.248546 | 40.085575 | 39.863805 | 39.596139 | 39.312541 | 39.023315 | 38.775840 | 38.600468 |
| 2 | 2.0 | 0.0 | NaN | 672.240682 | NaN | 627.197534 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 38.513961 | 39.059952 | 39.520749 | 39.787939 | 39.842868 | 39.704403 | 39.456068 | 39.184804 | 39.010760 | 39.084157 |
| 3 | 3.0 | 0.0 | NaN | 244.821079 | NaN | 215.568379 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 39.596341 | 39.756774 | 39.870106 | 39.887863 | 39.792020 | 39.596463 | 39.349100 | 39.088784 | 38.887460 | 38.820092 |
| 4 | 4.0 | 0.0 | NaN | 348.474546 | NaN | 267.460156 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 39.721842 | 40.106007 | 40.415270 | 40.559689 | 40.516298 | 40.304765 | 40.002072 | 39.680998 | 39.454527 | 39.454623 |
5 rows × 431 columns
df_out.meas_phi.hist(bins=100, )
<AxesSubplot:>
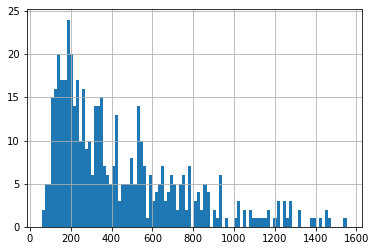
Now we see, using the same Phi threshold we obtain a larger number of “good enough” parameter sets:
good_enough = df_out.loc[df_out.meas_phi<acceptable_phi].index.values
print("number of good enough realisations:", good_enough.shape[0])
number of good enough realisations: 197
So sampling from the linearized posterior improves the chances of getting parameters that fit the data.
#ax = df_out.phi.hist(alpha=0.5)
df_out.loc[good_enough,"meas_phi"].hist(color="g",alpha=0.5)
plt.show()
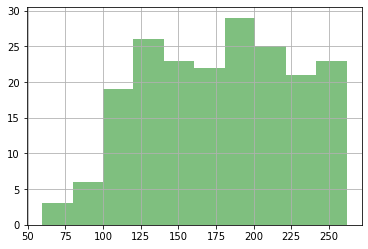
Check the forecasts again.
So although we are getting more “good enough” parameter sets, we are still failing to entirely capture the truth values of all forecasts (see “part_time” forecast). So our forecast posterior is overly narrow (non-conservative).
Why? Because our uncertainty analysis is not robust for all our forecasts, even with non-linear Monte Carlo. The parameterization scheme is still to coarse…
for forecast in pst.forecast_names:
ax = plt.subplot(111)
df_out.loc[:,forecast].hist(bins=10,alpha=0.5,color="0.5",ax=ax)
df_out.loc[good_enough,forecast].hist(bins=10,alpha=0.5,color="b",ax=ax)
v = pst.observation_data.loc[forecast,"obsval"]
ylim = ax.get_ylim()
ax.plot([v,v],ylim,"k--",lw=2.0)
ax.set_ylabel('count')
ax.set_title(forecast)
plt.tight_layout()
plt.show()
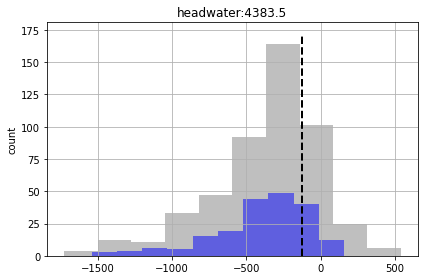
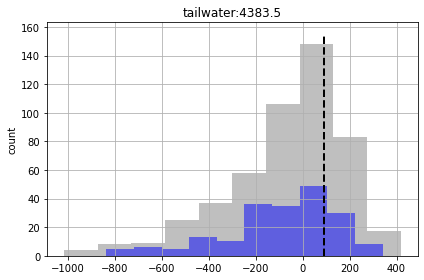
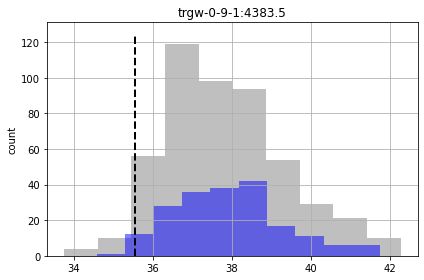
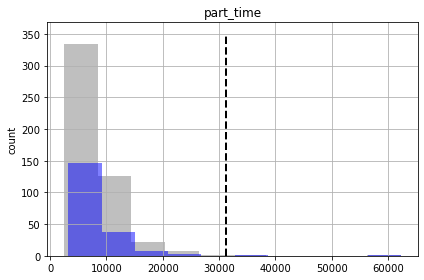
What have we learnt? Even though we are avoiding the assumptions of linearity required for FOSM, and burning a lot more silicone, this does not guarantee that the uncertainty analysis is conservative. Why? Because we are not considering relevant sources of parameter uncertainty. We are not accounting for spatial variability of porosity…boundary condition parameters (e.g. GHB, WEL and STR parameters)…temporal variability of recharge and pumping rates…and so on.
But we also saw that, with high-dimensional problems, these brute-force approaches to sampling the (non linear) posterior probability distribution get extremely computationaly expensive. In the past, the Null-Space Monte Carlo (Tonkin and Doherty, 2009) provided an option that reduced the burden of calibration-constrained Monte Carlo. More recently, ensemble methods such as are avialble in PEST++IES provide an even more efficient option.
We cover the use of PEST++IES in Part2 of these tutorials, where we introduce workflows for a very high-dimensional prameterisation scheme.