Local Parameter Sensitivity and Identifiability
Sensitivity analysis maks use of a Joacoban matrix to determine statistical insights into a model. We have already discussed the Jacobian matrix in a few places. It is calculated by perturbing the parameter (usually 1%) and tracking what happens to each observation. In a general form the sensitivity equation looks like eq. 9.7 Anderson et al. 2015:
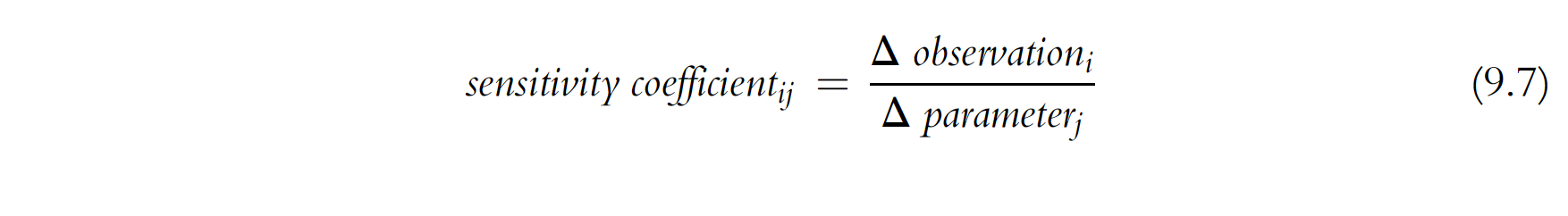
This is key for derivative-based parameter estimation because, as we’ve seen, it allows us to efficiently compute upgraded parameters to try during the lambda search. But the Jacobian matrix can give us insight about the model in and of itself.
Parameter Sensitivty
Recall that a Jacobian matrix stores parameter-to-observation sensitivities. For each parameter-observation combination, we can see how much the observation value changes due to a small change in the parameter. If $y$ are the observations and $x$ are the parameters, the equation for the $i^th$ observation with respect to the $j^th$ parameter is:
\(\frac{\partial y_i}{\partial x_j}\) This can be approximated by finite differences as :
\(\frac{\partial y_i}{\partial x_j}~\frac{y\left(x+\Delta x \right)-y\left(x\right)}{\Delta x}\)
Insensitive parameters (i.e. parameters which are not informed by calibration) are defined as those which have sensitivity coefficients larger than a modeller specified value (Note: this is subjective! In practice, insensitive parameters are usually defined has having a sensitiveity coeficient two orders of magnitude lower than the most sensitive parameter.)
Parameter Identifiability
Sensitivity analyses can mask other artifacts that affect calibration and uncertainty. A primary issues is correlation between parameters. For example, we saw that in a heads-only calibration we can’t estimate both recharge and hydraulic conductivity independently - the parameters are correlated so that an increase in one can be offset with an increase in the other. To address this shortcoming, Doherty and Hunt (2009) show that singular value decomposition can extend the sensitivity insight into parameter identifiability. Parameter identifiability combines parameter insensitivity and correlation information, and reflects the robustness with which particular parameter values in a model might be calibrated. That is, an identifiable parameter is both sensitive and relatively uncorrelated and thus is more likely to be estimated (identified) than an insensitive and/or correlated parameter.
Parameter identifiability is considered a “linear method” in that it assumes the Jacobian matrix sensitivities hold over a range of reasonable parameter values. It is able to address parameter correlation through singular value decomposition (SVD), exactly as we’ve seen earlier in this course. Parameter identifiability ranges from 0 (perfectly unidentifiable with the observations available) to 1.0 (fully identifiable). So, we typically plot identifiability using a stacked bar chart which is comprised of the included singular value contributions. Another way to think of it: if a parameter is strongly in the SVD solution space (low singular value so above the cutoff) it will have a higher identifiability. However, as Doherty and Hunt (2009) point out, identifiability is qualitative in nature because the singular value cutoff is user specified.
Limitations
As has been mentioned a couple of times now, sensitivity and identifiability assumes that the relation between parameter and obsevration changes are linear. These sensitivities are tested for a single parameter set (i.e. the parameter values listed in the PEST control file). This parameter set can be before or after calibration (or any where in between). The undelying assumption is that the linear relation holds.
In practice, this is rarely the case. Thus, sensitivities obtained during derivative-based parameter estimation is local. It only holds up in the vicinity of the current parameters. That being said, it is a quick and computationaly efficient method to gain insight into the model and links between parameters and simualted outputs.
An alternative is to employ global sensitivity analysis methods, which we introduce in a subsequent notebook.
References:
- Doherty, John, and Randall J. Hunt. 2009. “Two Statistics for Evaluating Parameter Identifiability and Error Reduction.” Journal of Hydrology 366 (1–4): 119–27. doi:10.1016/j.jhydrol.2008.12.018.
- Anderson, Mary P., William W. Woessner, and Randall J. Hunt. 2015. Applied Groundwater Modeling: Simulation of Flow and Advective Transport. Applied Groundwater Modeling. 2nd ed. Elsevier. https://linkinghub.elsevier.com/retrieve/pii/B9780080916385000018.
Admin
We are going to pick up where the “Freyberg pilot points” tutorials left off. The cells bellow prepare the model and PEST files.
import sys
import os
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore", category=DeprecationWarning)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt;
import shutil
sys.path.insert(0,os.path.join("..", "..", "dependencies"))
import pyemu
import flopy
assert "dependencies" in flopy.__file__
assert "dependencies" in pyemu.__file__
sys.path.insert(0,"..")
import herebedragons as hbd
plt.rcParams['font.size'] = 10
pyemu.plot_utils.font =10
# folder containing original model files
org_d = os.path.join('..', '..', 'models', 'monthly_model_files_1lyr_newstress')
# a dir to hold a copy of the org model files
working_dir = os.path.join('freyberg_mf6')
if os.path.exists(working_dir):
shutil.rmtree(working_dir)
shutil.copytree(org_d,working_dir)
# get executables
hbd.prep_bins(working_dir)
# get dependency folders
hbd.prep_deps(working_dir)
# run our convenience functions to prepare the PEST and model folder
hbd.prep_pest(working_dir)
# convenience function that builds a new control file with pilot point parameters for hk
hbd.add_ppoints(working_dir)
ins file for heads.csv prepared.
ins file for sfr.csv prepared.
noptmax:0, npar_adj:1, nnz_obs:24
written pest control file: freyberg_mf6\freyberg.pst
could not remove start_datetime
1 pars added from template file .\freyberg6.sfr_perioddata_1.txt.tpl
6 pars added from template file .\freyberg6.wel_stress_period_data_10.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_11.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_12.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_2.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_3.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_4.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_5.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_6.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_7.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_8.txt.tpl
0 pars added from template file .\freyberg6.wel_stress_period_data_9.txt.tpl
starting interp point loop for 800 points
took 1.982655 seconds
1 pars dropped from template file freyberg_mf6\freyberg6.npf_k_layer1.txt.tpl
29 pars added from template file .\hkpp.dat.tpl
starting interp point loop for 800 points
took 1.977726 seconds
29 pars added from template file .\rchpp.dat.tpl
noptmax:0, npar_adj:65, nnz_obs:37
new control file: 'freyberg_pp.pst'
Load the pst control file
Let’s double check what parameters we have in this version of the model using pyemu (you can just look in the PEST control file too.).
pst_name = "freyberg_pp.pst"
# load the pst
pst = pyemu.Pst(os.path.join(working_dir,pst_name))
# what parameter groups?
pst.par_groups
['porosity', 'rch0', 'rch1', 'strinf', 'wel', 'hk1', 'rchpp']
Which are adjustable?
# what adjustable parameter groups?
pst.adj_par_groups
['strinf', 'wel', 'hk1', 'rchpp']
We have adjustable parameters that control SFR inflow rates, well pumping rates, hydraulic conductivity and recharge rates. Recall that by setting a parameter as “fixed” we are stating that we know it perfectly (should we though…?). Currently fixed parameters include porosity and future recharge.
For the sake of this tutorial, let’s set all the parameters free:
par = pst.parameter_data
#update paramter transform
par.loc[:, 'partrans'] = 'log'
#check adjustable parameter groups again
pst.adj_par_groups
['porosity', 'rch0', 'rch1', 'strinf', 'wel', 'hk1', 'rchpp']
Calculate the Jacobian
First Let’s calculate a single Jacobian by changing the NOPTMAX = -2. This will need npar+1 runs. The Jacobian matrix we get is the local-scale sensitivity information
# change noptmax
pst.control_data.noptmax = -2
# rewrite the contorl file!
pst.write(os.path.join(working_dir,pst_name))
noptmax:-2, npar_adj:68, nnz_obs:37
num_workers = 10
m_d = 'master_local'
pyemu.os_utils.start_workers(working_dir, # the folder which contains the "template" PEST dataset
'pestpp-glm', #the PEST software version we want to run
pst_name, # the control file to use with PEST
num_workers=num_workers, #how many agents to deploy
worker_root='.', #where to deploy the agent directories; relative to where python is running
master_dir=m_d, #the manager directory
)
Sensitivity
Okay, let’s examing the local sensitivities by looking at the local gradients of parameters with respect to observations (the Jacobian matrix from the PEST++ NOPTMAX = -2 run)
We’ll use pyemu to do this:
#read the jacoban matrix
jco = pyemu.Jco.from_binary(os.path.join(m_d,pst_name.replace(".pst",".jcb")))
jco_df = jco.to_dataframe()
# inspect the matrix as a dataframe
jco_df = jco_df.loc[pst.nnz_obs_names,:]
jco_df.head()
| ne1 | rch0 | rch1 | strinf | wel5 | wel3 | wel2 | wel4 | wel0 | wel1 | ... | rch_i:32_j:17_zone:1.0 | rch_i:2_j:17_zone:1.0 | rch_i:22_j:2_zone:1.0 | rch_i:27_j:2_zone:1.0 | rch_i:22_j:12_zone:1.0 | rch_i:32_j:12_zone:1.0 | rch_i:12_j:17_zone:1.0 | rch_i:7_j:2_zone:1.0 | rch_i:7_j:17_zone:1.0 | rch_i:17_j:2_zone:1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gage-1:3652.5 | 0.0 | 5841.205981 | 0.0 | 1120.270879 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 220.487806 | 228.270528 | 161.600024 | 171.733547 | 238.729236 | 201.639433 | 240.762708 | 176.319517 | 233.832423 | 169.624779 |
| gage-1:3683.5 | 0.0 | 6435.657399 | 0.0 | 1144.361274 | -120.824878 | -63.328247 | -243.792499 | -15.308866 | -241.879117 | -167.669361 | ... | 240.753192 | 268.165732 | 169.644583 | 178.352181 | 260.887237 | 217.386450 | 275.172028 | 193.237184 | 271.628364 | 181.377647 |
| gage-1:3712.5 | 0.0 | 7097.077428 | 0.0 | 1149.171568 | -208.255099 | -134.286346 | -361.950602 | -42.397402 | -372.891340 | -283.110736 | ... | 282.870630 | 307.759930 | 172.678297 | 181.892606 | 293.654501 | 248.666346 | 317.577241 | 197.296498 | 313.073017 | 185.631787 |
| gage-1:3743.5 | 0.0 | 7932.862636 | 0.0 | 1152.525457 | -269.555554 | -201.182368 | -434.848044 | -77.830036 | -455.575631 | -365.438861 | ... | 331.992336 | 356.581877 | 177.606059 | 188.181135 | 334.154861 | 285.656487 | 369.250280 | 203.128798 | 363.746072 | 191.958304 |
| gage-1:3773.5 | 0.0 | 8593.599442 | 0.0 | 1153.402937 | -310.231299 | -255.387502 | -483.416828 | -113.758463 | -509.916327 | -424.120710 | ... | 364.964156 | 392.737790 | 183.785408 | 196.353881 | 364.893232 | 311.643036 | 406.855466 | 210.089888 | 400.851338 | 198.936449 |
5 rows × 68 columns
We can see that some parameters (e.g. rch0) have a large effect on the observations used for calibration. The future recharge (rch1) has no effect on the calibration observations, but that makes sense as none of the calibration observations are in that future stress period!
How about Composite Scaled Sensitivities
As can be seen above, parameter sensitivity for any given parameter is split among all the observations in the Jacobian matrix, but the parameter sensitivity that is most important for parameter estimation is the total parameter sensitivity, which reflects contributions from all the observations.
How to sum the individual sensitivities in the Jacobian matrix in the most meaningful way? In the traditional, overdetermined regression world, CSS was a popular metric. CSS is Composite Scaled Sensitivitity. It sums the observation weighted sensitivity to report a single number for each parameter.
In Hill and Tiedeman (2007) this is calculated as: \({css_{j}=\sqrt{\left(\sum_{i-1}^{ND}\left(\frac{\partial y'_{i}}{\partial b_{j}}\right)\left|b_{j}\right|\sqrt{w_{ii}}\right)/ND}}\)
In PEST and PEST++, it is calculated slightly differently in that scaling by the parameter values happens automatically when the parameter is subjected to a log-transform (and we can see above that all our parameters are logged). This is due to a correction that must be made in calculating the Jacobian matrix and follows from the chain rule of derivatives. Seems somewhat academic, but let’s compare the two.
Let’s instantiate a Schur object (see the “intro to fosm” tutorials) to calculate the sensitivities.
# instantiate schur
sc = pyemu.Schur(jco=os.path.join(m_d,pst_name.replace(".pst",".jcb")))
# calcualte the parameter CSS
css_df = sc.get_par_css_dataframe()
css_df.sort_values(by='pest_css', ascending=False).plot(kind='bar', figsize=(13,3))
plt.yscale('log')
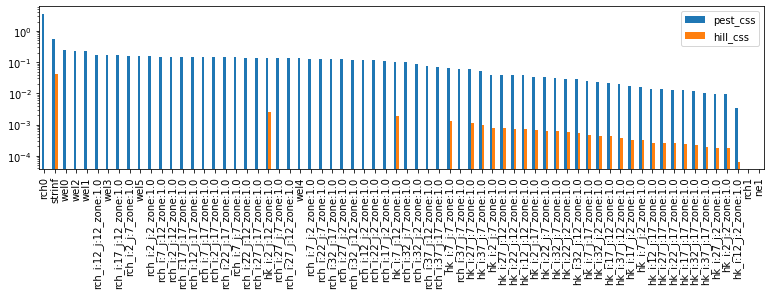
Note that the reltive ranks of the hk parameters agree between the two…but no so for the rchpp ilot point parameters, nor the rch0 parameter. According to pest_css the rch0 is the most sensitive. Not so for the hill_css. Why might this be?
hint: what is the initial value of
rch0? What is the log of that initial value?
Okay, let’s look at just the PEST CSS and rank/plot it:
What does this show us? It shows which parameters have the greatest effect on the objective function. In other words, sensitive parameters are those which are informed by observation data. They will be affected by calibration.
Parameters which are insensitive (e.g. rch1 and ne1), are not affected by calibration. Why? Because we have no observation data that affects them. Makes sense: rch1 is recharge in the future, ne1 is not informed by head or flow data - the only observations we have.
plt.figure(figsize=(12,3))
ax = css_df['pest_css'].sort_values(ascending=False).plot(kind='bar')
ax.set_yscale('log')
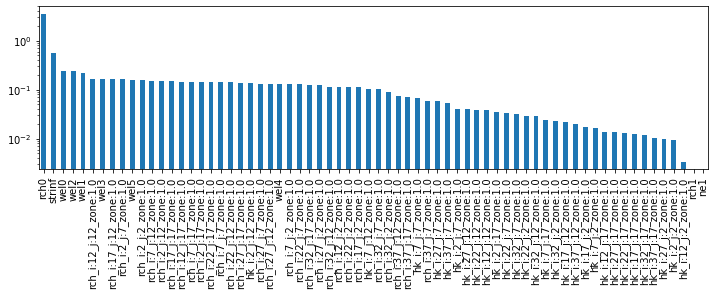
So how do these parameter sensitivities affect the forecasts?
Recall that the sensitivity is calculated by differencing the two model outputs, so any model output can have a sensitivity calculated even if we don’t have a measured value. So, because we included the forecasts as observations we have sensitivities for them in our Jacobian matrix. Let’s use pyemu to pull just these forecasts!
jco_fore_df = sc.forecasts.to_dataframe()
jco_fore_df.head()
| headwater:4383.5 | tailwater:4383.5 | trgw-0-9-1:4383.5 | part_time | |
|---|---|---|---|---|
| ne1 | 0.000000 | 0.000000 | 0.000000 | 10743.664245 |
| rch0 | -915.373459 | -564.544215 | 5.340906 | -1046.833537 |
| rch1 | -2091.812821 | -1539.075668 | 5.172705 | -401.726184 |
| strinf | 2.990537 | 8.439942 | 0.030474 | -18.054907 |
| wel5 | 10.105829 | 21.877808 | -0.043456 | -47.648042 |
Note that porosity is 0.0, except for the travel time forecast (part_time), which makes sense.
Perhaps less obvious is rch0 - why does it have sensitivity when all the forecasts are in the period that has rch1 recharge? Well what happened in the past will affect the future…
Consider posterior covariance and parameter correlation
Again, use pyemu to construct a posterior parameter covariance matrix:
covar = pyemu.Cov(sc.xtqx.x, names=sc.xtqx.row_names)
covar.df().head()
| ne1 | rch0 | rch1 | strinf | wel5 | wel3 | wel2 | wel4 | wel0 | wel1 | ... | rch_i:32_j:17_zone:1.0 | rch_i:2_j:17_zone:1.0 | rch_i:22_j:2_zone:1.0 | rch_i:27_j:2_zone:1.0 | rch_i:22_j:12_zone:1.0 | rch_i:32_j:12_zone:1.0 | rch_i:12_j:17_zone:1.0 | rch_i:7_j:2_zone:1.0 | rch_i:7_j:17_zone:1.0 | rch_i:17_j:2_zone:1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ne1 | 0.0 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | ... | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 |
| rch0 | 0.0 | 1.719625e+04 | 1.810695e-52 | 2.555628e+03 | -6.783684e+02 | -6.724618e+02 | -1.028452e+03 | -4.222311e+02 | -1.073359e+03 | -9.430636e+02 | ... | 5.877640e+02 | 6.794441e+02 | 4.933025e+02 | 5.225856e+02 | 6.698941e+02 | 5.495180e+02 | 6.840297e+02 | 5.619582e+02 | 6.801790e+02 | 5.135518e+02 |
| rch1 | 0.0 | 1.810695e-52 | 3.310813e-52 | 5.616738e-53 | -5.715799e-54 | -1.127573e-53 | -6.630929e-54 | -1.285323e-53 | -6.368659e-54 | -9.227413e-54 | ... | 1.425093e-54 | 3.042063e-54 | 1.010563e-53 | 9.151096e-54 | 4.022032e-54 | 2.977386e-54 | 2.348003e-54 | 1.235553e-53 | 2.578004e-54 | 1.145960e-53 |
| strinf | 0.0 | 2.555628e+03 | 5.616738e-53 | 4.244482e+02 | -1.107656e+02 | -1.053190e+02 | -1.681681e+02 | -6.071951e+01 | -1.758415e+02 | -1.547466e+02 | ... | 8.932119e+01 | 1.025931e+02 | 6.979899e+01 | 7.401507e+01 | 1.012322e+02 | 8.267088e+01 | 1.045795e+02 | 7.958081e+01 | 1.034567e+02 | 7.379336e+01 |
| wel5 | 0.0 | -6.783684e+02 | -5.715799e-54 | -1.107656e+02 | 3.373046e+01 | 3.380922e+01 | 5.037216e+01 | 2.104357e+01 | 5.249801e+01 | 4.679896e+01 | ... | -2.270078e+01 | -2.647943e+01 | -1.980311e+01 | -2.110747e+01 | -2.662822e+01 | -2.154104e+01 | -2.688474e+01 | -2.160801e+01 | -2.663027e+01 | -2.049266e+01 |
5 rows × 68 columns
For covariance, very small numbers reflect that the parameter doesn’t covary with another. (Does it make sense that rch1 does not covary with other parameters?)
We can visualize the correlation betwen the two parameters using a correlation coefficient
R = covar.to_pearson()
plt.imshow(R.df(), interpolation='nearest', cmap='viridis')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x21f83b62cd0>
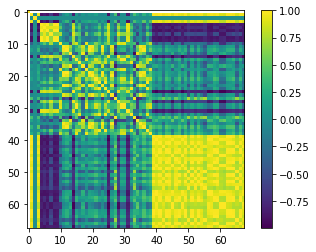
As expected, the parameters are correlated perfectly to themselves (1.0 along the yellow diagonal) buth they also can have appreciable correlation to each other, both positively and negatively.
Inspect correlation for a single parameter
Using pilot point hk_i:12_j:12_zone:1.0, let’s look only at the parameters that have correlation > 0.5
cpar = 'hk_i:12_j:12_zone:1.0'
R.df().loc[cpar][np.abs(R.df().loc[cpar])>.5]
hk_i:7_j:12_zone:1.0 0.968990
hk_i:2_j:7_zone:1.0 0.933603
hk_i:17_j:2_zone:1.0 0.593429
hk_i:12_j:17_zone:1.0 0.728918
hk_i:27_j:2_zone:1.0 0.747418
hk_i:7_j:7_zone:1.0 0.940472
hk_i:12_j:12_zone:1.0 1.000000
hk_i:17_j:12_zone:1.0 0.737877
hk_i:2_j:12_zone:1.0 0.959114
hk_i:7_j:17_zone:1.0 0.973001
hk_i:2_j:2_zone:1.0 -0.560843
hk_i:17_j:17_zone:1.0 0.520214
hk_i:2_j:17_zone:1.0 0.988199
hk_i:12_j:2_zone:1.0 0.902478
Name: hk_i:12_j:12_zone:1.0, dtype: float64
Saying parameters are correlated is really saying that when a parameter changes it has a similar effect on the observations as the other parameter(s). So in this case that means that when hk_i:12_j:12_zone:1.0 increases it has a similar effect on observations as increasing hk_i:2_j:12_zone:1.0. If we add a new observation type (or less powerfully, an observation at a new location) we can break the correlation. And we’ve seen this: adding a flux observation broke the correlation between R and K!
We can use this pyemu picture to interrogate the correlation - here we say plot this but cut out all that correlations under 0.5. Play with this by putting other numbers between 0.3 and 1.0 and re-run the block below.
R_plot = R.as_2d.copy()
R_plot[np.abs(R_plot)>0.5] = np.nan
plt.imshow(R_plot, interpolation='nearest', cmap='viridis')
plt.colorbar();
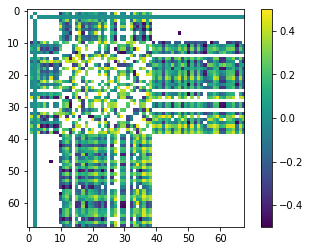
In practice, correlation >0.95 or so becomes a problem for obtainning a unique solution to the parameter estimation problem. (A problem which can be avoided with regularization.)
Identifiability
Parameter identifiability combines parameter insensitivity and correlation information, and reflects the robustness with which particular parameter values in a model might be calibrated. That is, an identifiable parameter is both sensitive and relatively uncorrelated and thus is more likely to be estimated (identified) than an insensitive and/or correlated parameter.
One last cool concept about identifiability the Doherty and Hunt (2009) point out: Because parameter identifiability uses the Jacobian matrix it is the sensitivity that matters, not the actual value specified. This means you can enter hypothetical observations to the existing observations, re-run the Jacobian matrix, and then re-plot identifiability. In this way identifiability becomes a quick but qualitative way to look at the worth of future data collection - an underused aspect of our modeling!
To look at identifiability we will need to create an ErrVar object in pyemu
ev = pyemu.ErrVar(jco=os.path.join(m_d,pst_name.replace(".pst",".jcb")))
We can get a dataframe of identifiability for any singular value cutoff (singular_value in the cell below). (recall that the minimum number of singular values will the number of non-zero observations; SVD regularization)
pst.nnz_obs
37
Try playing around with singular_value in the cell below:
singular_value= 37
id_df = ev.get_identifiability_dataframe(singular_value=singular_value).sort_values(by='ident', ascending=False)
id_df.head()
| right_sing_vec_1 | right_sing_vec_2 | right_sing_vec_3 | right_sing_vec_4 | right_sing_vec_5 | right_sing_vec_6 | right_sing_vec_7 | right_sing_vec_8 | right_sing_vec_9 | right_sing_vec_10 | ... | right_sing_vec_29 | right_sing_vec_30 | right_sing_vec_31 | right_sing_vec_32 | right_sing_vec_33 | right_sing_vec_34 | right_sing_vec_35 | right_sing_vec_36 | right_sing_vec_37 | ident | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| rch0 | 0.932378 | 1.316588e-02 | 0.005903 | 0.007991 | 0.000812 | 0.000609 | 0.000015 | 0.026758 | 0.001542 | 0.000247 | ... | 0.000013 | 0.000011 | 0.000008 | 0.000003 | 0.000012 | 0.000002 | 0.000003 | 0.000025 | 0.000004 | 0.999948 |
| strinf | 0.020741 | 2.305790e-01 | 0.006274 | 0.109774 | 0.540635 | 0.001327 | 0.017827 | 0.013370 | 0.004200 | 0.018371 | ... | 0.000947 | 0.000005 | 0.001093 | 0.000014 | 0.000115 | 0.000149 | 0.001975 | 0.000619 | 0.000213 | 0.995883 |
| wel4 | 0.000564 | 6.897222e-07 | 0.148021 | 0.048598 | 0.000400 | 0.362244 | 0.001291 | 0.044568 | 0.015191 | 0.017385 | ... | 0.001077 | 0.003035 | 0.009988 | 0.000156 | 0.002629 | 0.001476 | 0.007095 | 0.000422 | 0.000477 | 0.980652 |
| rch_i:2_j:7_zone:1.0 | 0.001488 | 4.154581e-02 | 0.002563 | 0.063259 | 0.000684 | 0.003269 | 0.361813 | 0.015770 | 0.014034 | 0.027443 | ... | 0.000753 | 0.052757 | 0.002842 | 0.006321 | 0.000134 | 0.000472 | 0.000382 | 0.000110 | 0.010223 | 0.978339 |
| wel1 | 0.002835 | 3.365628e-02 | 0.081648 | 0.057850 | 0.059161 | 0.016663 | 0.020086 | 0.110854 | 0.019189 | 0.068539 | ... | 0.010471 | 0.004439 | 0.003617 | 0.001581 | 0.000712 | 0.003628 | 0.012728 | 0.000625 | 0.001982 | 0.963266 |
5 rows × 38 columns
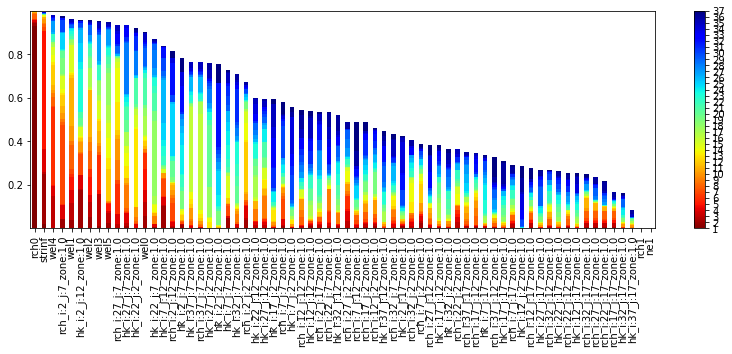
It’s easy to visualize parameter identifiability as stacked bar charts. Here we are looking at the identifiability with singular_value number of singular vectors:
id = pyemu.plot_utils.plot_id_bar(id_df, figsize=(14,4))
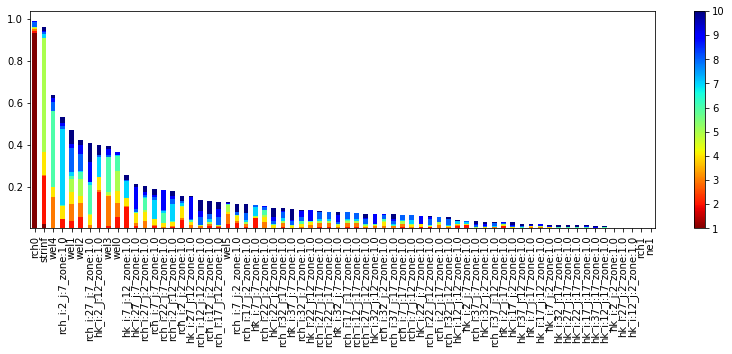
However, it can be more meaningful to look at a singular value cutoff:
id = pyemu.plot_utils.plot_id_bar(id_df, nsv=10, figsize=(14,4))
Display Spatially
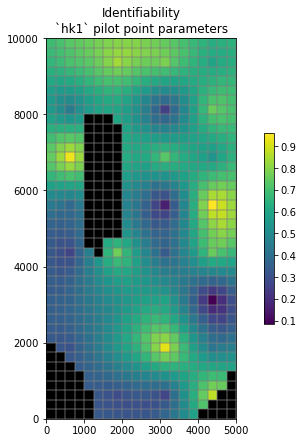
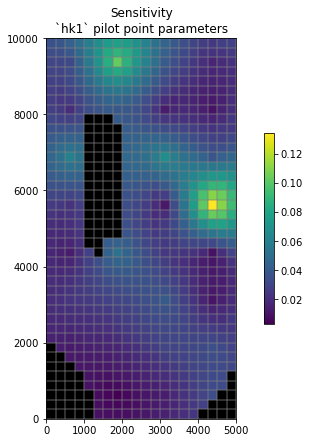
It can be usefull to display sensitivities or identifiabilities spatially. Pragmatically this can be acomplished by assigning sensitivity/identifiability values to pilot points (as if they were parameter values) and then interpolating to the model grid.
The next cells do this in the background for the hk1 pilot parameter identifiability.
# get the identifiability values of rthe hk1 pilot points
hkpp_parnames = par.loc[par.pargp=='hk1'].parnme.tolist()
ident_vals = id_df.loc[ hkpp_parnames, 'ident'].values
# use the conveninec function to interpolate to and then plot on the model grid
hbd.plot_arr2grid(ident_vals, working_dir)
could not remove start_datetime
We can do the same for sensitivity:
# and the same for sensitivity CSS
css_hk = css_df.loc[ hkpp_parnames, 'pest_css'].values
# use the conveninec function to interpolate to and then plot on the model grid
hbd.plot_arr2grid(css_hk, working_dir, title='Sensitivity')
could not remove start_datetime
So what?
So what is this usefull for? Well if we have a very long-running model and many adjstable parameters - and if we really need to use derivative-based parameter estimation methods (i.e. PEST++GLM) - we could now identify parameters that can be fixed and/or omitted during parameter estimation (but not uncertainty analysis!).
Looking at forecast-to-parameter sensitivities can also inform us of which parameters matter for our forecast. If a a parameter doesnt affect a forecast, then we are less concerned with it. If it does…then we may wish to give it more attention. These methods provide usefull tools for assessing details of model construction and their impact on decision-support forecasts of interest (e.g. assessing whether a boundary condition affects a forecast).
But! As has been mentioned - these methods are local and assume a linear relation between parameter and observation changes. As we have seen, this is usualy not the case. A more robust measure of parameter sensitivity requires the use of global sensitivity analysis methods, discussed in the next tutorial.